** Yann Herklotz

Hi! I’m currently a PhD student in the Circuits and Systems group at Imperial College London, supervised by John Wickerson.
My research focuses on formalising the process of converting high-level programming language descriptions to correct hardware that is functionally equivalent to the input. This process is called high-level synthesis (HLS), and allows software to be turned into custom accelerators automatically, which can then be placed on field-programmable gate arrays (FPGAs). An implementation in the Coq theorem prover called Vericert can be found on Github.
I have also worked on random testing for FPGA synthesis tools. Verismith is a fuzzer that will randomly generate a Verilog design, pass it to the synthesis tool, and use an equivalence check to compare the output to the input. If these differ, the design is automatically reduced until the bug is located.
** Contact
Here are some ways to contact me:
- GPG fingerprint
A34A 550C A362 BE1A 3CFB 8C8D 852C 9E32 302D 38F4yann [at] yannherklotz [dot] com- Social
- Twitter:
@ymherklotz - Mastodon:
@ymherklotz@types.pl - IRC (Libera Chat):
ymherklotz
- Twitter:
- Code
- Github:
ymherklotz - Gitlab:
ymherklotz - Sourcehut:
~ymherklotz - Personal Git:
git.ymhg.org
- Github:
** Blog
*** Blog Index
Here you can find all my previous posts:
*** TODO Writing a Program as a State-Machine in Hardware
- Moore and Mealy are normally the distinctions that are made for state machines.
- This is not that useful for hardware state-machines, especially of real programs.
- Instead, one can use the distinctions made by Pedroni, Volnei A (2013).
*** Downloading Academic Papers Automatically
I’ve been using ebib as my bibliography manager for the last three years of my PhD, and have loved how integrated it is into Emacs. Whether writing in org-mode, LaTeX or ConTeXt, I can get autocompletion for all of my references from my main bibliography file, and insert native citation commands for the language that I am currently writing in. It even supports creating a sub-bibliography file containing only the references that are used by the current project, but is linked to my main bibliography file so that changes propagate in both directions. It also has powerful filtering options that make it easy to group and find related papers. However, the main reason I wanted to learn it initially was because of the extensibility that is inherent to an Emacs-based application.
**** Automatic ID Generation
The first useful feature that ebib provides is the automatic ID generation, which reuses the
internal BibTeX ID generation provided by Emacs (bibtex-generate-autokey). I had already used the
automatic ID generation with org-ref, and had changed the generation function slightly so that it
did not generate colons in the key name, and had already used on my bibliography file. The
following is a great feature of Emacs and Lisp, which allows you to wrap an existing function with
more code so that this extra code gets executed every time the original function is called. In this
case it does a string replacement to remove any colons on the output of the original function.
(advice-add 'bibtex-generate-autokey :around
(lambda (orig-func &rest args)
(replace-regexp-in-string ":" "" (apply orig-func args))))
As ebib reuses this function, my advice that I added around that function was automatically used by all the automatic ID generation that ebib used and I therefore did not need to configure anything else for it to behave properly for me.
**** Automatic Paper Downloads
Ebib allows for a lot of extra content to be stored together with your bibliography entry. It handles this extra information nicely because it always uses the ID of the entry as a way to store this extra information without having to create additional entries inside of the bib file. I use this mainly to store notes associated to papers as well as store their PDF version. This allows me to go to any entry in ebib and just press ‘N’ to view the associated notes, or ‘f’ to open the PDF (inside of emacs of course). However, the latter assumes that you have manually downloaded the PDF associated with that bib entry into the right folder and named it after the key of the entry in the bib file. I used to do this manually, but it took quite a bit of work and seemed like something I should automate.
The first step is just figuring out how to get the ID of the current entry when in the ebib index
buffer (the one that lists all the bib entries). I know of a function which can already copy the
key when hovering over the entry, which is bound to C k, so we can have a look at what function is
executed when pressing these keys, using the lovely builtin describe-key function, and then at how this function is implemented by using
describe-function, which also gives you the source code for the
function (which you can obviously modify as you want and reevaluate to change the behaviour at
runtime). We then find out that we can use the following function to retrieve the key of the entry:
ebib--get-key-at-point. For example, if we want to create a function
that will check if a file exists for the current entry, we can write the following:
(defun ebib-check-file ()
"Check if current entry has a file associated with it."
(interactive)
(let ((key (ebib--get-key-at-point)))
(unless (file-exists-p (concat (car ebib-file-search-dirs) "/" key ".pdf"))
(error "[Ebib] No PDF found."))))
When executing this function in the ebib index buffer, we will get an error if the file is not
present, or nothing at all. ebib-file-search-dirs in this case
contains a list of directories that should be searched for a file associated with the current entry
(and we only care about the first one in this case).
Then, if the file is not present, we want to download the PDF, so we now want to write a simple
download function. Let’s focus on getting papers from the ACM first. In emacs we can download a
file from a URL using the url-copy-file function, so all we need is
generate a URL to pass to that function. To do that we can check a few PDFs in the ACM and check
what the URL looks like. Luckily, it seems like it’s based on the DOI for the paper, which should
be available in the bib entry, so we can write the following function:
(defun acm-pdf-url (doi)
"Generate the URL for a paper from the ACM based on the DOI."
(concat "https://dl.acm.org/doi/pdf/" doi))
This of course assumes that you have access to the paper, either because it’s open access or because you have access through your university. We can then download it from there using the following:
(defun download-pdf-from-doi (key doi)
"Download pdf from doi with KEY name."
(url-copy-file (acm-pdf-url doi) (concat (car ebib-file-search-dirs) "/" key ".pdf")))
And then wrap it in a top-level function which can then be called interactively, and will retrieve all the important information from the current bib entry in ebib.
(defun ebib-download-pdf-from-doi ()
"Download a PDF for the current entry."
(interactive)
(let* ((key (ebib--get-key-at-point))
(doi (ebib-get-field-value "doi" key ebib--cur-db 'noerror 'unbraced 'xref)))
(unless key (error "[Ebib] No key assigned to entry"))
(download-pdf-from-doi key doi)))
As you can see, we can get values for arbitrary fields using the ebib-get-field-value function,
which I also found using the trick above concerning getting the key.
This will only work with papers from the ACM, but we can easily add support for other publishers such as Springer, IEEE and arXiv. This is mainly straightforward, except for the IEEE where I needed to realise that in most cases they use the last few numbers of the DOI as their indexing number, so I had to implement the function as follows:
(defun ieee-pdf-url (doi)
"Retrieve a DOI pdf from the IEEE."
(when (string-match "\\.\\([0-9]*\\)$" doi)
(let ((doi-bit (match-string 1 doi)))
(concat "https://ieeexplore.ieee.org/stampPDF/getPDF.jsp?tp=&arnumber=" doi-bit "&ref="))))
ArXiv is also a bit special because it normally puts it’s own unique codes into the ’eprint’ field.
A More Robust Downloader
We now have all these functions that can download PDFs from various sources, but we just need a way to decide which URL to use. We could ask the user to choose when they want to download the PDF, but I argue that there is normally enough information in the bib entry to automatically choose. The final heuristic I came up with, which seems to mostly work well, is the following:
(defun download-pdf-from-doi (key &optional doi publisher eprint journal organization url) "Download pdf from DOI with KEY name." (let ((pub (or publisher "")) (epr (or eprint "")) (jour (or journal "")) (org (or organization "")) (link (or url ""))) (url-copy-file (cond ((not doi) link) ((or (string-match "ACM" (s-upcase pub)) (string-match "association for computing machinery" (s-downcase pub))) (acm-pdf-url doi)) ((string-match "arxiv" (s-downcase pub)) (arxiv-pdf-url epr)) ((or (string-match "IEEE" (s-upcase pub)) (string-match "IEEE" (s-upcase jour)) (string-match "IEEE" (s-upcase org))) (ieee-pdf-url doi)) ((string-match "springer" (s-downcase pub)) (springer-pdf-url doi)) (t (error "Cannot possibly find the PDF any other way"))) (concat (car ebib-file-search-dirs) "/" key ".pdf"))))It looks at the DOI, publisher, eprint, journal, organization and a URL. Then, it first checks if it got a DOI, which if it didn’t means that the URL should be used. Then, it checks if the publisher is the ACM using different possible spellings, and if so uses the ACM link to download the PDF. Then it checks if the publisher is arXiv, and uses the eprint entry to download it. IEEE is the trickiest, as it can appear in various locations based on the conference or journal of the original entry. We therefore check the publisher field, journal field and organization filed. Finally, we check if the publisher is Springer and download it from there.
**** Automatic Syncing of Papers to a Remarkable Tablet
Finally, reading papers on your laptop or on the desktop is not a great experience. I therefore got myself a Remarkable tablet, which has served me greatly for taking notes as well as reading papers. The main selling point of the tablet is the extremely low latency for drawing and writing on the tablet compared to other E Ink tablets. However, it also has a nifty feature which makes it ideal to read papers even though it’s essentially an A5 piece of paper. You can crop PDF margins which make them much more readable without having to zoom in and move around the PDF, and this cropping is consistent when turning pages as well as opening and closing the PDF. I also love that it runs Linux instead of other tablets which usually run Android.
However, one downside is that it has a pretty closed source ecosystem with respect to the applications used for syncing files to the tablet. However, there is also a great community around the Remarkable to counteract this, for example the great rmapi tool which allows for downloading and uploading files from the command-line, or the lines-are-rusty tool which produces SVG from Remarkable lines files.
Therefore, we can use rmapi to sync all the files in my biblography to the remarkable, by just running:
ls *.pdf | xargs -n1 rmapi put
which will try to upload all my files every time I call it, but nicely enough it fails quickly whenever the file already exists on the Remarkable.
**** Links
*** TODO About the Promise of Performance from Formal Verification
When one thinks about formal verification, one normally associates this with sacrificing performance for an improvement in reliability. However, this does not necessarily have to be the case. In this post I’ll try and argue for why
*** TODO Reasoning about logic
- Interesting extension from binary logic.
- Has subtle differences in terms of Axioms.
- This can lead to various different logics, especially implication.
Binary logic is pervasive in computing, as it is used to model low-level hardware primitives as well as reason about complex code using modern SMT solvers.
**** Example reasoning about results of computations
- Computations can sometimes not be evaluatable.
- You get three results.
- We want to prove properties about it.
**** Trying Standard Three-Valued Logic
*** Introduction to Luhmann’s Zettelkasten writingemacs
Niklas Luhmann’s Zettelkasten is becoming increasingly popular for being a great note taking
technique. However, it is often misunderstood as taking notes without any structure, whereas Luhmann
actually structured his notes hierarchically, but also allowed for arbitrary links between
notes. This post will describe the general note-taking workflow that Luhmann used and a practical
implementation of the Zettelkasten in Emacs’ built-in org-mode, which I have been using regularly
for my notes and has been working well.
**** Zettelkasten compared to other note-taking solutions
I have gone through many different phases of note taking, from trying to keep handwritten notes in a folder, to using digital notes organised by topic, or notes organised by tags. None of these methods really worked for me though, either I would not be able to find the relevant notes anymore, or I wouldn’t really be able to figure out the best place to put a note.
There are various existing note taking solutions that people have come up with other the years, so why care about the technique that Luhmann used? What intrigued me the most about this technique is that it combined what I liked about structuring my notes in a linear and hierarchical fashion, with links to other notes which added an element of unstructured notes. This way, notes can just be written in any linear fashion one chooses, and link to any other note if the topics are similar enough. In addition to that, even though notes are written in a linear fashion, one can always add new notes in between any other notes, meaning one does not have to worry too much about writing notes one after another that are not too related. And whenever one wants to discuss a topic, it can always be branched off into a new sequence of notes.
This method is far more flexible than other note-taking methods I used before, but also less stressful as it is designed in a way that the actual organisation of the notes does not matter too much in the end. In addition to that, if time is set aside to try and link notes together once in a while, or when a new note is inserted, then it should be straightforward to try and find relevant notes again. Even though finding a specific note again isn’t that easy, as they may be nested deeply in a structure that may not be directly related to the subject, if these are linked back to other notes of the same topic it should be possible to explore these eventually when the notes are looked at again at some point in the future. After some time, it may also be necessary to build manual indices for sub topics in the notes which links to a few notes that relate to the topic.
**** General setup
When writing notes using this method, you do not have to think too much about where the note should go. However, the first thing to check is whether there is a note that may already be similar enough to the note you want to insert. An example setup could be the following, which is separated into three topics: (1) high-level synthesis (HLS), (2) computing and (3) verification.
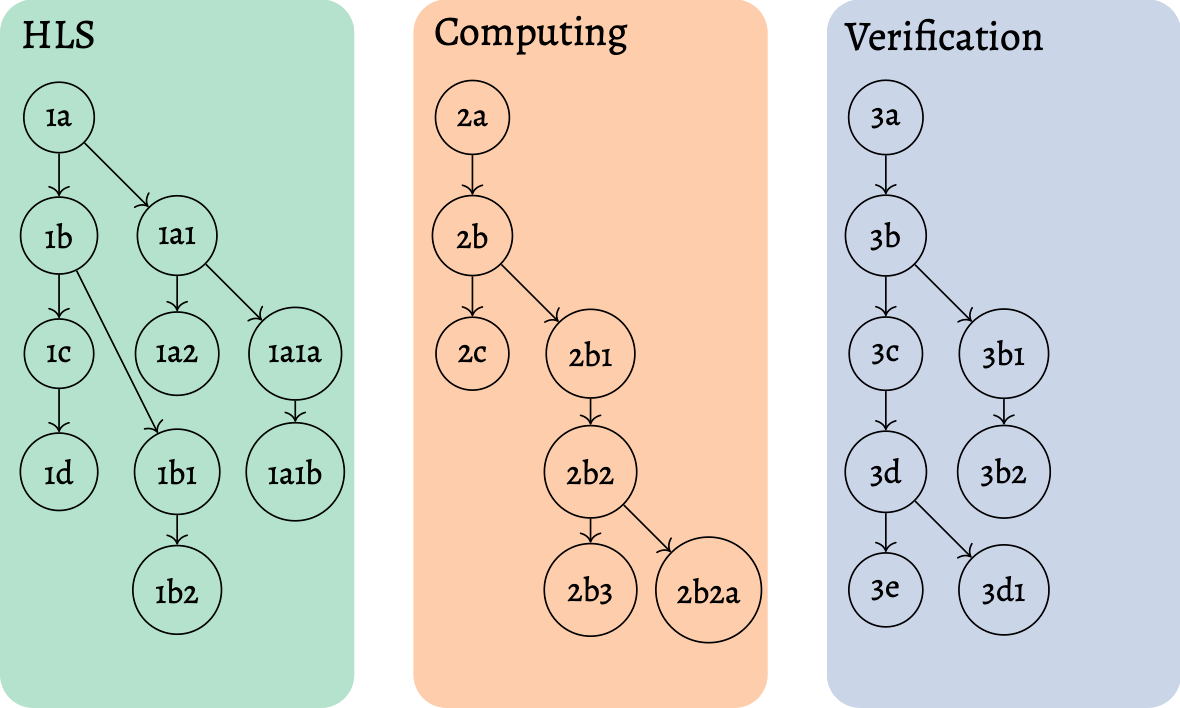
Figure 1: The first step is to create a tree of notes in any hierarchy that seems to suit it best. Because of the numbering of the notes, other notes can always be inserted in between notes by adding a letter or number to the end.
We can then add notes as shown above, adding them into the right category under a heading that makes
the most sense, thereby building a tree. Each note is assigned a unique identifier (ID), which it
can then be referred to later. These identifiers contain either numbers or letters, where sequential
notes just increment the last number or letter in the ID. Then, if a note needs to be added to a
note that already has a successor, a branch can be created by taking the ID and adding a 1 or an a
at the end of it to create the new ID.
After having a tree like that, the idea is that notes can be interconnected in any way that seems fit, if the contents of the note are generally relevant to the other note. This results in the diagram below that still has the general structure of the tree but also contains interconnections to other notes that might be in a completely different topic but might still be generally relevant.
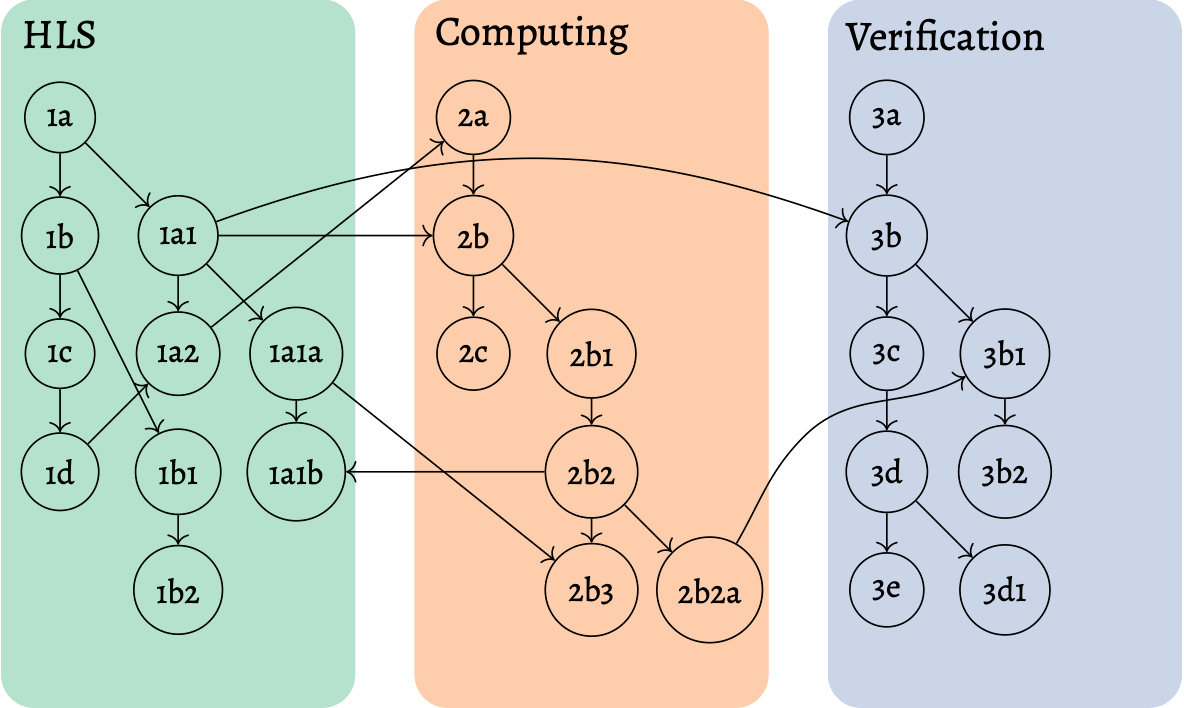
Figure 2: Once in a while, links to other notes in other categories or in the same category should be made.
This allows for notes to be written anywhere that makes sense, but still connect to other areas in the notes that also might be relevant, thereby creating a network of relevant notes that might connect these topics in different ways. This means that it is easy to jump around from topic to topic by following relevant notes around, adding more links if these come up and making them permanent by adding them to the right notes. The hope is that this eventually leads to a second brain where all the links between topics and notes are permanently there. This leads to it being possible to browse the brain explicitly and observe the connections that were made that may have been forgotten and therefore lead to new discoveries.
**** Inserting new notes
There are several possible notes that can be inserted into the Zettelkasten, but the need for them should arise naturally and one therefore doesn’t have to think about the separate types of notes directly. In addition to the following types of notes, Luhmann also had a separate box for references and notes about those references, however, these are not added to the Zettelkasten in my case because I felt like using tools specifically to keep track of references is a better system for me. This is mentioned further in the keeping track of references section.
Permanent notes
Inserting new notes into the Zettelkasten can be done for any new piece of information one wants to permanently add to the tree of notes and therefore the network of notes. These are therefore called “permanent notes,” however, these are not the only notes that may appear in the network. The most important thing to take into consideration is that “permanent notes” should be completely in your own words, and express an idea that also links to other parts in the network. At the start it may be necessary to create a few topics that these notes fit into, however, eventually one should be able to find notes that are similar enough which this new note should follow.
Index notes
Apart from that, there can also be “index notes,” which try to give some structure to a subsection that may have gotten lost with all of the branches that may have been added. In addition to that, these may tie in other notes from other topics as well that relate to that topic. These can therefore just be added whenever you feel like there are too many notes for a subtopic and cannot keep track of all the possible links.
**** Keeping track of references
Luhmann kept track of references by inserting them into their own box in a linear structure and then referring to them by ID whenever they needed to be cited. These are often called “bibliographical notes.” In addition to that, notes that were not permanent and more relevant to a specific paper or book were also added separately to the other notes and were called “literature notes,” as these often contained summaries of the papers or books that were cited. Even though these were written in his own words, they only really were relevant to the paper itself as temporary notes, which could eventually be added as “permanent notes” into the Zettelkasten and linked to other notes when a narrative developed that did link this piece of knowledge to other notes.
As references are quite separate to the other notes anyways, I prefer to keep them quite separate as well, and instead use standard bibliography management tools to keep track of all my references as well as linking notes to the references in the tool itself. In my case this is using ebib in Emacs, however, any alternative works as well, such as Zotero.
In my notes, I then reference these by their bibtex identifier that is automatically generated, and which is later used when referencing the same literature in LaTeX, for example. This allows me to keep these notes quite separate and forces me to think about links when I do eventually add them to the network as “permanent notes.”
**** Emacs implementation
If anything touches plain text, then it is possible to efficiently implement it using org-mode in
Emacs. org-mode already has most of the functionality that is needed for taking notes in this way,
we just have to show the layout that I am currently using for note taking.
org-mode is a plain text file format that can be used from simple note taking to a complete task
tracker with an agenda and organisation system. It can easily be adapted to implement the note
taking described in this post. The first step to create the notes directory is just to think about a
note one would want to write, and what a general topic is that it could fit into. A file for that
topic can then be created, for example, my topics are the following:
hls.org: my notes on high-level synthesis,verification.org: my notes on verification, andcomputing.org: my notes on computer science topics.
A screenshot of how the top-level view of all my files looks like is shown in the screenshot below.
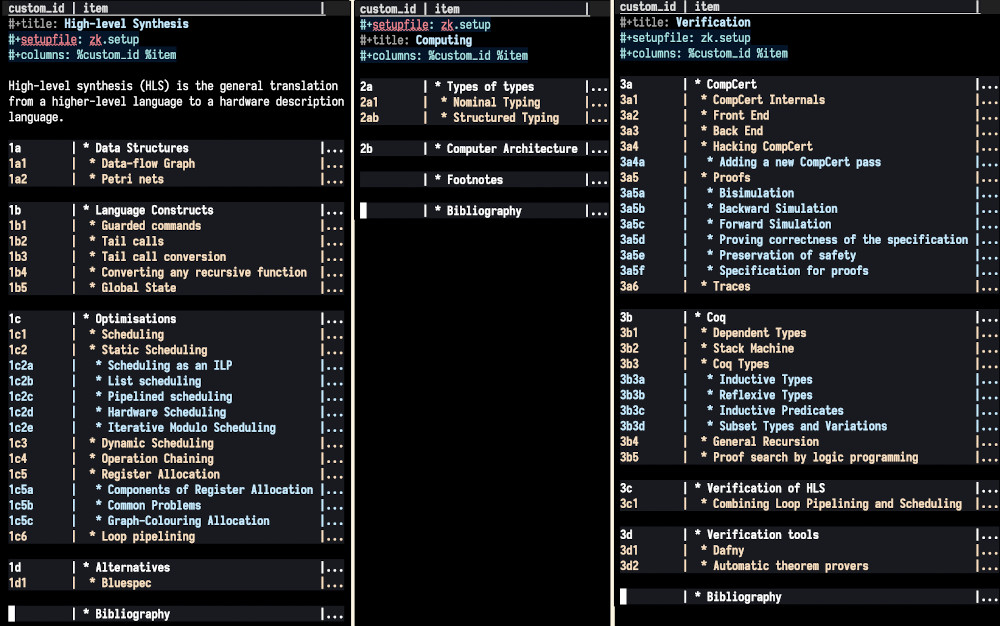
Figure 3: Example of the files containing the three topics I take notes in, displayed using the columns view in org-mode.
Next, we can keep adding notes to the respective files, and whenever we can see a possible link between two notes, we can add that to the relevant note. However, once in a while we have to take time to go through a lot of the notes and try to make conscious links between other topics and add the relevant links.
Linking to other notes
The main feature that is needed is linking to other notes and assigning IDs to existing notes so that these can be referenced. In
org-mode, this can be done using theCUSTOM_IDproperty, which can be set for every header and then linked to easily using a simpleorg-modelink. The only problem is that theCUSTOM_IDthen needs to be created manually from the previous one, however, this can be automated as shown in the automatic ID creation section.
Some automation for ID creation
Finally, to conclude we can also add some automation to creating new notes. The first function we’ll need is one which generates an ID for us. We’ll need two functions, one which increments the current ID, and one which will branch off of the current ID and create a parallel one. We can therefore first create a simple
ymhg/incr-idfunction which simply increments the last character of the ID.(defun ymhg/incr-id (ident) (let ((ident-list (string-to-list ident))) (cl-incf (car (last ident-list))) (concat ident-list)))However, one problem is that if we get to an ID with a
9, it will stop incrementing correctly and turn into a:,1 which will break the naming scheme. This could simply be fixed by turning the last value of the ID into a number, incrementing that, then turning it back into the original representation. However, for the current purpose we’ll just assume that manual intervention will be required sometimes. Then, to create the function that generates an ID branching off of the current one, we just have to check if the current id ends with a number or a character, and add aaor1accordingly.(defun ymhg/branch-id (ident) (if (string-match-p ".*[0-9]$" ident) (concat ident "a") (concat ident "1")))Finally, we just need functions that create a new headline underneath the current one, with the correct level and the correct ID. To do this, we first need two functions, one which creates a new function that gets the ID of the current heading, generate the new heading, and then insert a new heading and generate the new ID for that heading. We can then write a similar function that instead generates a branching ID and creates a subheading compared to the same-level heading. However, as these functions are extremely similar, the only differences being what heading to add and how to increment the ID, we can create a general function that will get an ID, increment it and then generate a new heading somehow using that ID.
(defun ymhg/org-zettelkasten-create (incr newheading) (let* ((current-id (org-entry-get nil "CUSTOM_ID")) (next-id (funcall incr current-id))) (funcall newheading) (org-set-property "CUSTOM_ID" next-id)))Using that general function, we can then first create the function that will insert a heading at the same level as the previous heading and increments the last value of the ID.
(defun org-zettelkasten-create-heading () (ymhg/org-zettelkasten-create 'ymhg/incr-id 'org-insert-heading))Then we create the function that will increment the ID by adding an
aor1after the ID, and inserts a sub-heading.(defun org-zettelkasten-create-subheading () (ymhg/org-zettelkasten-create 'ymhg/branch-id '(lambda () (org-insert-subheading ""))))For the final part of automation, we can then create a function that will correctly use the
create-nextandcreate-branchfunction depending on the current location of the cursor. To see which function should be used. The main idea behind this function is that we first go back to the current heading usingorg-back-to-headingand then try and go forward to the next heading which is at the same level usingorg-forward-heading-same-level. If these are at different locations, then we know that there is a next heading on the same level, which means that we need to branch off of the current one. If we are still in the same location, then we can create a new note at the same level.(defun org-zettelkasten-create-dwim () (interactive) (let ((current-point (save-excursion (org-back-to-heading) (point))) (next-point (save-excursion (org-forward-heading-same-level 1 t) (point)))) (if (= current-point next-point) (org-zettelkasten-create-heading) (org-zettelkasten-create-subheading))))Finally, we can then add the
create-dwimfunction to our keybinding map and we’re ready to create as many notes as possible.(define-key org-mode-map (kbd "C-c y n") #'org-zettelkasten-create-dwim)
**** Conclusion
To conclude, there are currently many approaches that try to mimic Luhmann’s Zettelkasten, however,
I don’t believe that many actually follow his philosophy that closely, and therefore lose on some of
the benefits that this note-taking technique provides. I therefore preferred implementing it as
simply as possible and leveraging the powerful org-mode to get a system that works for me.
I do not pretend to have the perfect implementation of a digital Zettelkasten, and there are many features that are still missing, such as a keyword index, which Luhmann used as an alternative index into the Zettelkasten. However, for now I haven’t had a need for that yet, and therefore have not thought about how to best implement it. It could always be implemented manually like Luhmann did, but it could also be implemented automatically by using tags, for example. In addition to that, there are other note-taking tools, especially roam research-like tools, which provide a lot of functionally for unordered notes, such as seeing a directed acyclic graph (DAG) view of your notes and provide back-links to other notes that refer to this note.
I hope this post helps when maybe choosing an existing implementation, of which there are plenty, and to see if these have all the features that you need or want from a note-taking tool. If that is not the case, I hope that I have also convinced you that creating your own does not have to be painful and that it really does not inherently need many features. I will also be following this up with a post on how to use the Zettelkasten to write blog posts or papers and organising them using these notes.
*** Nix for Coq Development nixcoq
I first learnt about Nix because of Haskell, eventually running into cabal hell while working on many different projects simultaneously. These used the same dependencies but with different versions, which could not be handled by cabal. The common solution is to use the stack build tool. This manages a database of compatible libraries in called stackage which contains a snapshot of hackage packages that have been tested together. This works very well for packages that are on stackage, however, if one uses dependencies that are only on hackage or, even worse, only available through git, it can become hard to integrate these into stack and use them. In addition to that, if one depends on specific versions of command line tools, these can only be documented and will not be installed or tracked by stack.
The other option is to use Nix, which is a general purpose package manager. The feature that sets it
apart from other package managers is that it completely isolates every package using hashes and can
therefore seamlessly support multiple versions of the same package. This inherently eliminates the
cabal hell problem. In addition to that, if you create a nix derivation (name for a nix package) for
the current project one is working on, you can launch a shell containing the exact versions that
were specified in the derivation to let it build. This also gives Nix the ability to act as a
package manager for reproducible builds, instead of needing to resort to Docker. In addition to
that, Nix provides one command, nix-build, which will build the whole project.
For projects using Coq, this is exceptionally useful as one can specify dependencies for Coq, OCaml and the shell using the same nix derivation, and launch a shell which contains all the right versions which will let the project build.
**** Nix Basics
First, to understand nix derivations it is important to go over some Nix basics and explain the language itself, as it is quite different to usual package descriptions. The most interesting fact about the language is that it is purely functional, only using immutable data structures.
The most important thing to know when learning a new language is where to look up existing functions and new syntax for that language. This is particularly important for Nix as it does not have that big of a presence on stackoverflow, and it can be hard to google for the Nix language as that is often an abbreviation “*nix” used for linux. I therefore tend to google for the term “nixpkgs” instead of “nix” which seems to give better results. The main resources are the following:
- the amazing Nix manual, especially the Nix expression chapter,
- Nix pills for a collection of useful tutorials, and finally
- the Nix contributors guide for more information about how to package derivations.
Searching for anything on those sites should be much more useful than using Google.
There are three main important structures that need to be understood in Nix. There are
- sets (
{ a = 2; b = 3; }), - lists (
[ 1 2 3 4 ]), and - functions (
pattern: body).
These are the structures you will come across most often, however, there are many other useful features Nix has that makes it pleasant to work with.
Just like many other functional languages, Nix has let expressions which bind an expression to a
name.
let name = expr; in body
It also supports importing an expression, which just evaluates and inserts an expression.
import ./expression.nix;
The with expression is also interesting, which makes all the attributes of a set available in the
next expression, unqualified.
with set; expr
There are many other useful constructs such as recursive sets (allows you to refer to keys from the
set inside the set), inheriting (copy the current scope into a set or let expression) or
conditionals (if c then e1 else e2). However, this should be enough to learn about derivations.
**** Nix Integration with Coq
I’ll go through an example of how I created a nix derivation for a Coq project which extracted to OCaml, going through all the steps that were necessary to make it more general. Each package in nix is actually a derivation. These are functions that take in the whole collection of all the derivations that are available, select the derivations that are needed using the pattern matching that functions inherently do and returns a new derivation. This is just a set containing information on how to build the package by defining multiple different stages in the build pipeline.
The main function we will use is the mkDerivation helper function which is a wrapper around the more
manual derivation function. This function takes in a set which can be used to override various build
stages and dependencies.
This example will build a Nix derivation for the Vellvm, so that it builds without any errors and contains all the nix packages that are required.
The first derivation one could come up with is the following, which is just a declaration of all the
packages that are needed. The with declaration can be used to bring all the members of the <nixpkgs>
set into scope. We then call the mkDerivation function to override some of the attributes inside the
set, such as the name (name), the location of the source code (src). These are the only two required
attributes for the mkDerivation function, however, that does not mean it will build yet.
with import <nixpkgs> {};
stdenv.mkDerivation {
# Name of the derivation.
name = "coq${coq.coq-version}-vellvm";
# Location of the source code which is available on GitHub.
src = fetchGit {
url = "https://github.com/vellvm/vellvm";
};
}
To actually get it to build, there are a few attributes that we need to specify in addition to
those. The first is customise the build step using the buildPhase attribute. By default, the build
will just execute make, however, in this project the makefile is actually in the src directory. We
therefore have to change to that directory first before we can do anything.
{ ...;
buildPhase = ''
cd src && make
''; }
This will now execute the makefile correctly, however, it will fail the build because Vellvm has a
few dependencies that need to be installed first. These are described in the README, so we can just
try and find them in Nix and can add them as build dependencies. Here we can specify Coq
dependencies using coqPackages, OCaml dependencies using ocamlPackages, and finally command line
tools such as the OCaml compiler or the OCaml build system dune.
{ ...; buildInputs = [ git coq ocamlPackages.menhir dune coqPackages.flocq
coqPackages.coq-ext-lib coqPackages.paco
coqPackages.ceres ocaml ]; }
Finally, Nix will execute make install automatically at the end to install the program correctly. In
this case, we need to set the COQLIB flag so that it knows where to place the compiled Coq
theories. These can be set using the installFlags attribute.
{ ...; installFlags = [ "COQLIB=$(out)/lib/coq/${coq.coq-version}/" ]; }
We then have the following Nix derivation which should download Vellvm and build it correctly.
with import <nixpkgs> {};
stdenv.mkDerivation {
name = "coq${coq.coq-version}-vellvm";
src = ./.;
buildInputs = [ git coq ocamlPackages.menhir dune coqPackages.flocq
coqPackages.coq-ext-lib coqPackages.paco
coqPackages.ceres ocaml ];
buildPhase = ''
cd src && make
'';
installFlags = [ "COQLIB=$(out)/lib/coq/${coq.coq-version}/" ];
}
However, one last problem we’ll have is that coqPackages.ceres does not actually exist in
coqPackages, we were a bit too optimistic. To solve this, however, we can easily define a derivation
for ceres from the GitHub repo and insert it as a dependency into the set. Luckily ceres has a nice
makefile at the base of the repository and does not have any external dependencies, except for Coq
itself. We can therefore define a derivation in the following way. We can use propagatedBuildInputs
to define dependencies that the package needs and that derivations using this package will also
need. In this case, any derivation using ceres will need Coq, otherwise it would not be useful.
let ceres = stdenv.mkDerivation {
name = "coq${coq.coq-version}-ceres";
src = fetchGit {
url = "https://github.com/Lysxia/coq-ceres";
};
propagatedBuildInputs = [ coq ];
installFlags = [ "COQLIB=$(out)/lib/coq/${coq.coq-version}/" ];
}; in
Finally, we can use a let expression to insert it as a dependency into our own derivation. We now
have a complete nix expression that will always build Vellvm correctly in a containerised manner.
nix-prefetch-url --unpack https://github.com/Lysxia/coq-ceres/archive/4e682cf97ec0006a9d5b3f98e648e5d69206b614.tar.gz
with import <nixpkgs> {};
let
ncoq = coq_8_10;
ncoqPackages = coqPackages_8_10;
ceres = ncoqPackages.callPackage
( { coq, stdenv, fetchFromGithub }:
stdenv.mkDerivation {
name = "coq${coq.coq-version}-ceres";
src = fetchFromGitHub {
owner = "Lysxia";
repo = "coq-ceres";
rev = "4e682cf97ec0006a9d5b3f98e648e5d69206b614";
sha256 = "0n3bjsh7cb11y3kv467m7xm0iygrygw7flblbcngklh4gy5qi5qk";
};
buildInputs = with coq.ocamlPackages; [ ocaml camlp5 ];
propagatedBuildInputs = [ coq ];
enableParallelBuilding = true;
installFlags = [ "COQLIB=$(out)/lib/coq/${coq.coq-version}/" ];
} ) { } ;
in
stdenv.mkDerivation {
name = "coq${coq.coq-version}-vellvm";
src = fetchGit {
url = "https://github.com/vellvm/vellvm";
};
buildInputs = [ git ncoq ocamlPackages.menhir dune ncoqPackages.flocq
ncoqPackages.coq-ext-lib ncoqPackages.paco ceres ocaml ];
buildPhase = ''
cd src && make
'';
installFlags = [ "COQLIB=$(out)/lib/coq/${coq.coq-version}/" ];
}
If one saves the file in default.nix, one can then build the nix expression using the nix-build
command. This should return a binary that runs the compiled OCaml code, which was extracted from
Coq.
*** MSR PhD Workshop on Next-Generation Cloud Infrastructure workshopFPGA
Microsoft Research held their first PhD Workshop which focused on new technologies for the cloud. The main themes of the workshop were optics and custom hardware. The workshop was spread over two days and included a keynote by Simon Peyton Jones on how to give a research talk, talks about three projects that are investigating various optical solutions (Silica, Sirius and Iris) and finally a talk on Honeycomb by Shane Fleming, replacing CPU’s in the database storage by custom hardware using FPGAs.
The workshop also included two poster sessions, and all the attendees presented the current projects that were being worked. These were also quite varied and included projects from various universities and also covered topics from optical circuits and storage to custom hardware and FPGAs. I presented our work on Verismith, our Verilog synthesis tool fuzzer.
I would like to thank Shane Fleming for inviting us to the workshop, and also thank all the organisers of the workshop.
**** Microsoft projects
Four microsoft projects were presented, with the main themes being custom hardware and optical electronics.
Honeycomb: Hardware Offloads for Distributed Systems
A big problem that large cloud infrastructures like azure suffer from is the time it takes to retrieve data from databases. At the moment, storage is setup by having many nodes with a CPU that accesses a data structure to retrieve the location of the data that it is looking for. The CPU then accesses the correct location in the hard drives, retrieves the data, and finally sends it to the correct destination.
General CPUs incur a Turing Tax, meaning that because they are so general, they become more expensive and less efficient than specialised hardware. It would therefore be much more efficient to have custom hardware that can walk the tree structure to find out the location of the data that it is trying to access, and then also access it.
The idea is to use FPGAs to catch and process the network packet requesting data, fetch the data from the correct location and then return it through the network. Using an FPGA means that each network layer can be customised and reworked for that specific use case. Even the data structure can be optimised for the FPGA so that it becomes extremely fast to traverse the data and find it’s location.
Silica: Optical Storage
The second talk was on optical storage which is a possible solution for archiving data. Today, all storage is done using either magnetic storage (tapes and hard drives), discs or flash storage (SSDs).
Flash storage is extremely expensive and is therefore not ideal for archiving, instead, it is fast and often used as the main storage.
Discs can maybe only store 300GB and there are physical limitations which stop the storage from growing. However, as the storage is done by engraving the disc. Even there, the life time of the disc is not permanent, as the film on the disc becomes bluish over time.
To archive a lot of data for a long time, the current solution is to use magnetic storage, as it is very cheap. However, the problem with magnetic storage is that it inherently degrades with time, and therefore extra costs are incurred every few years when migrating the data to new discs.
We therefore need a storage solution that will not degrade with time and is compact enough to store a lot of data. The answer to this is optical storage. Data is stored by creating tiny deformities in the glass using a femtosecond laser, which can then be read back using LEDs. The deformities have different properties such as angle and phase which dictate the current value at that location.

Figure 4: Project silica: image of 1978 “Superman” movie encoded on silica glass. Photo by Jonathan Banks for Microsoft.
Sirius: Optical Data Center Networks
With the increased use of fiber in data centers, the cost of switching using electronic switches increases dramatically, because the light needs to be converted to electricity first, and then converted back after the switch. This incurs a large latency in the network because that process takes a long time.
Instead, one can switch on the incoming light directly using optical switches, which reduce the switching latency to a few nanoseconds. This makes it possible to have fully optical data-centers.
Iris: Optical Regional Networks
Finally, project Iris explores how regional and wide area cloud networks could be designed to work better with the growing network traffic.
**** How to Give a Research Talk
Simon Peyton Jones gave the first talk which was extremely entertaining and insightful. He really demonstrated how to give a good talk, and at the same time gave great advice on how to give a good talk, with tips that applied to conference talks as well as broader talks. The slides used Comic Sans but that only showed how good a talk can if one doesn’t mind that.
The main things that should be included in a talk are:
- Motivation of the work (20%).
- Key idea (80%).
- There is no 3.
The purpose of the motivation is to wake people up so that they can decide if they would be interested in the talk. Most people will only give you two minutes before they open their phone and look at emails, so it is your job as the speaker to captivate them before they do that. Following this main structure, his advice is that introductions and acknowledgements should not come at the start of the talk, but should only come at the end of the talk. If the introductions are important, these could also come after the main motivation.
The rest of the talk should be on the key idea of the project, and it should on explaining the idea deeply to really satisfy the audience. Talks that only briefly touch on many areas often leaves the audience wanting more. However, this does not mean that the talk should be full of technical detail and slides containing complex and abstract formulas. Instead, examples should be given wherever possible, as it is much easier to convey the intuition behind the more general formulas. Examples also allow you to show edge cases which may show the audience why the general case is maybe not as straightforward as they are thinking.
*** Verismith verilogsynthesishaskellFPGA
Most hardware is designed using a hardware description language (HDL) such as Verilog or VHDL. These languages allow some abstraction over the hardware that is produced so that it is more modular and easier to maintain. To translate these hardware descriptions to actual hardware, they can be passed through a synthesis tool, which generates a netlist referring to the specific hardware connections that will appear in the actual hardware.
Furthermore, high-level synthesis (HLS) is also becoming more popular, which allows for a much more behavioural description of the circuit using a standard programming language such as C or OpenCL. However, even designs written in these languages need to be translated to an HDL such as Verilog or VHDL and therefore also need to rely on a synthesis tool.
Fuzzing is a way to randomly test tools to check if their behaviour remains correct. This has been very effective at finding bugs in compilers, such as GCC and Clang. CSmith, a C fuzzer, found more than 300 bugs in these tools by randomly generating C programs and checking that all the C compilers execute these programs in the same fashion. We therefore thought it would be a good idea to test synthesis tools in a similar fashion and improve their reliability. There are three main sections that I’ll go over to explain how we fuzz these tools: Verilog generation, Equivalence checking and Verilog reduction.
**** Verilog Generation
To test these tools, we have to first generate random Verilog which can be passed to the synthesis tool. There are a few important properties that we have to keep in mind though.
First, the Verilog should always have the same behaviour no matter which synthesis tool it passes through. This is not always the case, as undefined values can either result in a 1 or a 0.
Second, we have to make sure that our Verilog is actually correct and will not fail synthesis. This is important as we are trying to find deep bugs in the synthesis tools and not just it’s error reporting.
Once we have generated the Verilog, it’s time to give it to the synthesis tools to check that the output is correct. This is done using a formal equivalence check on the output of the synthesis tool.
**** Equivalence Check
The synthesis tools output a netlist, which is a lower level description of the hardware that will be produced. As the design that we wrote is also just hardware, we can compare these using the various equivalence checking tools that exist. This mathematically proves that the design was the same as the netlist.
If this fails, or if the synthesis tool crashed as it was generating the netlist, we want to then locate the cause for the bug. This can be done automatically by reducing the design until the bug is not present anymore and we cannot reduced the Verilog further.
**** Verilog Reduction
To find the cause of the bug, we want to reduce the design to a minimal representation that still shows the bug. This can be done by cutting the Verilog design into two, and checking which half still contains the bug. Once we do this a few times at different levels of granularity, we finally get to a smaller piece of Verilog code that still executes the bug in the synthesis tool. This is then much easier to analyse further and report to the tool vendors.
**** Results
In total, we reported 12 bugs to all the synthesis tools that we tested. A full summary of the bugs that were found can be seen in the Github repository.
**** Resources
The following resources provide more context about Verismith:
- Verismith FPGA ‘20 paper
- Verismith thesis
- Verismith slides: Presented to the Circuits and Systems group at Imperial College on the 01/07/2019 and at FPGA ‘20 on 25/02/2020.
- Verismith poster: Presented at the Microsoft Research PhD Workshop on 25/11/2019.
*** Realistic Graphics graphics
To explore realistic graphics rendering, I have written two Haskell modules on two different techniques that are used in graphics to achieve realism. The first project is a small lighting implementation using a latitude longitude map, the second one is an implementation of the median cut algorithm. The latter is used to deterministically sample an environment map.
A latitude longitude map is a 360 degree image which captures the lighting environments
**** Mirror Ball
To use a latitude longitude map when lighting a sphere in the environment, the reflection vector at every point on the sphere is used to get it’s colour. As a simplification, the sphere is assumed to be a perfect mirror, so that one reflection vector is enough to get the right colour.

Figure 5: Figure 1: Urban latitude and longitude map.
The latitude longitude map was created by taking a photo of a mirror ball and mapping the spherical coordinates to a rectangle.

Figure 6: Figure 2: Normals calculated on a sphere.
The first step is to calculate the normals at every pixel using the position and size of the sphere. These can be visualised by setting the RGB to the XYZ of the normal at the pixel.

Figure 7: Figure 3: Reflection vectors calculated on a sphere.
The reflection vector can then be calculated and visualised in the same way, by using the following formula: \(r = 2 (n \cdot v) n - v\).

Figure 8: Figure 4: Final image after indexing into the latitude longitude map using reflection vectors.
The reflection vector can be converted to spherical coordinates, which can in turn be used to index into the lat-long map. The colour at the indexed pixel is then set to the position that has that normal.
**** Median Cut
The median cut algorithm is a method to deterministically sample an environment map. This is achieved by splitting the environment map along the longest dimension so that there is equal energy in both halves. This is repeated n times recursively in each partition. Once there have been n iterations, the lights are placed in the centroid of each region. Below is an example with 6 splits, meaning there are 2^6 = 64 partitions.

Figure 9: Figure 5: Latitude longitude map of the Grace cathedral.
The average colour of each region is assigned to each light source that was created in each region.

Figure 10: Figure 6: After running the median cut algorithm for 6 iterations.
Finally, these discrete lights can be used to light diffuse objects efficiently, by only having to sample a few lights.

Figure 11: Figure 7: The radiance at each individual sample.
*** Jekyll to create a portfolio website web
Jekyll is a static site generator written in ruby that can be used in conjunction with Github Pages to create a great platform for displaying projects and writing blog posts.
The reason Jekyll is great for portfolio websites, especially if you are writing blogs at the same time, is because it handles the organisation of the portfolio projects and blog posts really well, and allows the posts to be written in markdown. This means that it makes the process of writing blog posts much easier, and also more readable in text format than using HTML.
In addition to that, Jekyll uses the liquid templating language to make HTML more modular and reusable, and it means that one does not have to rewrite the same HTML code multiple times. Jekyll also introduces many variables that can be used with liquid that contain information about the blog posts or projects, such as images associated with them, their excerpt or their title. This is very convenient to produce portfolio pages with previous of the projects, by having all the information in the project markdown files.
**** File Organisation
By default, Jekyll only supports blog posts that get put into a _posts directory, however, it is
extensible enough to allow for different types of posts, which are called collections in Jekyll.
My layout, which supports project descriptions for a portfolio and blog posts, looks like the following.
.
├── assets
│ ├── css
│ ├── fonts
│ ├── img
│ │ └── logos
│ └── js
├── _data
├── _includes
├── _layouts
├── _portfolio
└── _posts
**** Portfolio Collection
To make Jekyll recognise the _portfolio directory, it has to be declared in Jekyll’s configuration
file _config.yml.
collections:
portfolio:
output: true
Jekyll will now parse and turn the markdown files into HTML. To get a coherent link to the files, it is a good idea to add a permalink to the YAML front matter like the following.
---
title: FMark
permalink: /portfolio/fmark/
---
This means that the file will then be accessible using https://www.website.com/portfolio/fmark/.
**** Using Jekyll Parameters
Now that we have generated the portfolio directory, and have written the descriptions to a few projects, we can see how we can use the Jekyll variables that are to our disposal in Liquid.
First of all, to generate a great view on the main page of some of the projects that you have made, you can use a for loop to iterate through the projects, and even use a limit to limit the projects to a specific number. This can be useful when showing a few projects on the main page, and also want a page displaying all the projects.
{%- raw -%}
{% assign proj_reverse = site.portfolio | reverse %}
{% for project in proj_reverse limit: 3 %}
{% endraw %}
By default, the projects are listed from earliest to latest, so to display the three latest projects, the list first has to be reversed.
Inside the for loop, variables like
{%- raw -%}
{{ project.title }}
{{ project.excerpt }}
{% endraw %}
can be used to access the variables declared in the YAML, to generate views of the projects.
**** Conclusion
In conclusion, Jekyll and Liquid make it very easy to organise projects and make it easy to write the descriptions and blogs using markdown.
*** Noise Silencer DSP
The paper and the code are also available.
We wrote a Real Time DSP system on a TI chip that would reduce any noise from any signal in real time, using approximations of what the noise spectrum looks like, and subtracting that from the original spectrum of the signal.
*** FMark markdownFsharp
FMark is a markdown parser that features many extensions to GFM (Github Flavoured Markdown), such as macros, spread sheet functionality, and more extensions described below. It was written in a test driven manner, using purely functional F#.
**** Introduction
The markdown parser is written and implemented in F#. Even though there is an available module, called FSharp.Formatting that is also written in F# that supports markdown parsing and converting the output to HTML, we decided to write our own markdown parser. In addition to the simple parser, a lot of extensions were added to support the features mentioned below:
- GFM parsing
- Custom macro support
- Spread sheet functionality
- Citations and Footnote support
- Full HTML generation
A Visual Studio Code extension was also developed to integrate the parser into and editor and make it more useable.
**** Motivation
The main motivation for this project was to create a more powerful version of markdown that could be used to easily take notes in lectures.
Re-implementation of the Parser
Instead of using the FSharp.Formatting module, it was decided that the parser should be re-implemented. We found that the FSharp.Formatting module was not generic enough and did not allow as easy implementation of the extensions we wanted to add to markdown.
**** Custom Features
Macros
Macros were a feature that we thought should definitely be added to the parser, as it allows for a large extensibility, as the markdown parser also supports full HTML pass-through. This means that macros can be created that contain pure HTML which will be output in exactly the same way, and enables the addition of things like text boxes or colourful boxes.
Spread Sheet
Sometimes it is useful to directly do calculations in tables, as they are often used to display information. This can then be used to make tables more generic and not have to copy all the values over once something changes.
*** Emotion Classification using Images ML
We wrote a Convolutional Neural Network that would classify images into the 6 base emotions. We used tensorflow and python to design the network and train it.
*** YAGE graphics
YAGE is a fully featured 2D game engine written in C++ using OpenGL to render textured quads to the screen. It also includes an efficient and extensible Entity Component System to handle many different game objects. In addition to that, it provides a simple interface to draw shapes to a window and efficient texturing using Sprite Batching.
**** Goal of the Engine
YAGE is a personal project that I started to learn about computer graphics, using tools like modern OpenGL to learn about the graphics pipeline and common optimisations that are used in a lot of game engines.
However, writing the complete engine has taught me a lot more in addition to that, such as efficient memory management by taking advantage of caching to keep load times short and the number of textures that can be drawn high.
*** Emacs as an Email Client emacs
Emacs is a very powerful editor, therefore there are many benefits from using it as an email client, such as direct integration with org-mode for todo and task management or the amazing editing capabilities of Emacs to write emails.
However, Emacs cannot do this natively, but there is great integration with a tool called mu. This
tool is an indexer for your emails, and keeps track of them so that they are easily and quickly
searchable. The author of this tool also wrote an emacs-lisp file that queries mu and provides a
user interface in emacs to better interact with it and use it to read emails.
mu requires the emails to already be on the computer though, so the first step is to download them
using IMAP.
**** Downloading Emails
IMAP is a protocol that can be used to download a copy of your emails from the server. A great tool
to use to download them using IMAP is mbsync. In arch linux, this tool can be downloaded from the
official repository using
sudo pacman -S isync
This command line utility has to first be set up using a config file, which is usually located in
~/.mbsyncrc, so that it knows where to download the emails from and how to authenticate properly.
The most important parts to set up in the config file are
IMAPAccount gmail
Host imap.gmail.com
User user@gmail.com
Pass password
SSLType IMAPS
CertificateFile /etc/ssl/certs/ca-certificates.crt
to setup the account, and then the following to setup the directories where it should download emails to
IMAPStore gmail-remote
Account gmail
MaildirStore gmail-local
Subfolders Verbatim
Path ~/.mail/gmail/
Inbox ~/.mail/gmail/Inbox
Channel gmail
Master :gmail-remote:
Slave :gmail-local:
Patterns *
Create Both
SyncState *
It should then be mostly ready to download all the emails. If using two factor authentication, one can generate an app password which can be used instead of the user password.
Once mbsync is configured, the emails can be downloaded using
mbsync -a
**** Indexing the Emails
Once they are downloaded (in this case in the ~/.mail directory), they have to be indexed so that
they can quickly be searched using Emacs. This is done by using the following shell command.
mu index --maildir=~/.mail
However, as mu also has an emacs-lisp plugin, the following will also work after it has been
configured correctly in emacs.
emacsclient -e '(mu4e-update-index)'
Emacs Configuration
To use
muin emacs as well, one first has to load the emacs lisp file using(require 'mu4e)After that,
mu4ecan be configured with different things like the home directory, and shortcuts that should be used in emacs. The full configuration can be seen in my Emacs configuration, which is hosted on Github
**** Sending Emails
Sending emails from Emacs requires a different protocol which is SMTP, however, that is already included in Emacs. The most basic setup can be seen below.
(smtpmail-smt-user . "email@gmail.com")
(smtpmail-local-domain . "gmail.com")
(smtpmail-default-smtp-server . "smtp.gmail.com")
(smtpmail-smtp-server . "smtp.gmail.com")
(smtpmail-smtp-service . 587)
**** Conclusion
Emacs is now ready to be used as a full featured email client.
*** CPU Introduction hardware
The best way to understand how a processor works in detail is to create one from scratch or, in my case, write a software simulation of one. This was one of our assignments for our Computer Architecture course, and required us to to implement a Mips I processor, as it was not too complex, but did implement the fundemental ideas of a processor and how it operates.
**** Quick introduction to processors
What is a processor?
A processor is a digital circuit that receives instructions and exectues them sequentially. These instructions can be anything from branching instructions, that go to a different location in the code, to arithmetic instructions that can add two numbers together. Instructions are normally stored in memory and are produced by a higher level language such as C or C++ using a compiler. However, other languages exist as well, such as python, that run using an interpreter, which compiles the files on the fly and runs them. The image above shows a possible basic setup for a processor, which in this case is the Mips I processor.
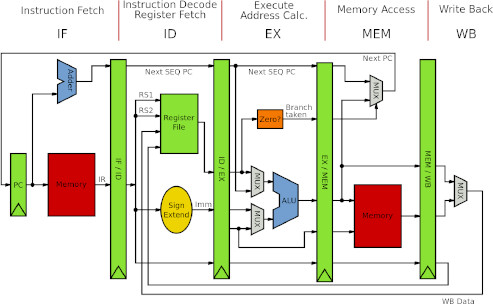
Figure 12: Mips processor layout.
A processor also has to be able to store information to be able to execute these instructions. Normally, processors have a small number of registers that are suited for this purpose. This number varies between architectures such as Arm, Mips and intel, but in this case the Mips processor has 32 registers. These registers are 32 bit wide, which means they can store an integer or an address to a location in memory, which can then be used to load data from.
Types of Processors
There are two main types of processor architectures, RISC and CISC processors. RISC processors are designed around the principle that the actual circuit should be as simple as possible, which means that the instructions have to be fairly simple too. The advantage of this is that the circuit and the actual processor gets simpler to build and optimise, however, it also means that the compiler that will eventually turn a program into instructions, will have to be clever about optimisations it makes, so as to minimise the amount of instructions. Examples of a RISC processor is an Arm process or a MIPS processor.
In contrast to this, a CISC processor is much more complex when looking at the architecture and has many more instructions than a RISC processor, that will often do multiple things at once. The advantage of this is that the compiler does not have to be as clever anymore, as there are many instructions that correspond directly with something that a programmer wants to do in the code, however, it means that the complexity of the hardware increases by a lot.
*** C to MIPS32 Compiler
The compiler was made to translate C code to MIPS assembly. It was then tested using qemu and
simulating the MIPS processor to run the binary.
What is a compiler?
A Compiler is a program that transforms code written in one language into another language. This is normally done to transform a higher level language such as C, into a lower level language such as assembly.

Figure 13: Compiler Workflow
Project
The project was separated into three parts: lexer, parser and the actual compiler. The lexer was written in flex, which then got passed to the parser that we wrote in bison. The AST (Abstract Syntax Tree) that was output by bison was then traversed in the compiler and the corresponding assembly code was output by the compiler.
In our second year we were given a coursework to write a compiler that would take in C89 code and compile it to MIPS32 assembly. We then used the gcc assembler to compile that to a binary and used qemu to simulate a MIPS processor and run the binary.
**** Lexer
TODO Part about lexer
**** Parser
TODO Part about parser
**** Compiler
TODO Part about compiler
*** Mips Processor hardware
The MIPS I architecture is quite simple when comparing it to different RISC CPU’s such as ARM. The five pipeline stages have distinct purposes and each instruction has a clear meaning. It also does not contain that many optimisations, which leads to loads and branches introducing delay slots. However, this makes it perfect to implement for a simulation of a CPU.
I implemented a clock cycle accurate simulation of a MIPS I CPU, which supports most MIPS I instructions.
*** FPGA Note Reader hardwareFPGA
In our first year of uni, we built a real-time music note reader using an FPGA and a camera. It can read custom sheet music and play it in real-time. The pitch is also adjustable using a blue marker placed anywhere in front of the camera.
Switching out the sheet music while it was playing a piece, and hearing the notes change to the new song was magical.
**** Design
The three main parts of the project were
- offline automatic music sheet conversion
- real time note reading
- real time music playing while showing the current note being played
Music Sheet Conversion
The custom music sheet is a grid which represents different notes that are to be played.

Figure 14: Custom music sheet as a grid.
The notes are encoded in binary in each column using 5 bits which allows for 32 different pitches. The grid supports 32 different notes that are played sequentially.
The grid is automatically converted by a program we wrote using OpenCV called NoteReader. The main method used to detect the stave and the individual notes for simple sheet music was to generate a histogram of intensities vertically and horizontally. Below is an example of this process using twinkle twinkle little star as an example.

Figure 15: Horizontal histogram.

Figure 16: Vertical histogram.
The maximum was then used to as a threshold value to determine the individual notes and where the stave lines and notes were located.

Figure 17: Notes detected and turned grey
The grid can then be generated by encoding the pitch of the note as a 5 bit binary number and drawing the grid.
One problem that was encountered during the generation was that the detection algorithm only worked on one line at a time, and threw away the rest of the sheet music. In addition to that, it was hard to test the grid generation and the note detection at the same time. We solved this by first generating a file with all the notes present, then uses that file to generate the grid. This allowed the grid generation and note detection to be completely separated and independent of each other, making them much easier to test as well.
Real-time Note Reading
The purpose of the custom grid is to allow the FPGA to read the notes and then play them in real time. The grid is designed so that the orientation can be picked up by the FPGA easily using two red markers in the top two corners. Now that the FPGA has the orientation and size of the grid, it can detect all the squares that define the notes. It goes through the grid columns sequentially and reads the notes as 5 bits.
Real-time Note Playing
Once a note is detected from the grid, the 5 bit number has to be converted to a frequency so that the note can be played. The frequencies are stored in a look-up table in the FPGA, which can be indexed using the 5 bit number.
A wave generator then outputs a square wave with the required frequency through one of the GPIO pins on the FPGA board. Using a low-pass filter and an amplifier, the square wave is transformed into a continuous sinusoidal wave. This wave is passed to a speaker so that the tone is heard.
** Books
The following is a non-exhaustive list of books I’ve read.
*** 2022
*** – 2021
- The Hitchhiker’s Guide to the Galaxy, by Douglas Adams
- The Restaurant at the End of the Universe, by Douglas Adams
- Life, the Universe and Everything, by Douglas Adams
- So Long, and Thanks for All the Fish, by Douglas Adams
- Foundation, by Isaac Asimov
- L’Étranger, by Albert Camus
- Le Mythe de Sisyphe, by Albert Camus
- Réflexions sur la peine capitale, by Albert Camus
- Call for the Dead, by John le Carré
- A Murder of Quality, by John le Carré
- The Spy Who Came in from the Cold, by John le Carré
- The Mysterious Affair at Styles, by Agatha Christie
- Murder on the Orient Express, by Agatha Christie
- A Study in Scarlet, by Arthur Conan Doyle
- The Sign of the Four, by Arthur Conan Doyle
- The Adventures of Sherlock Holmes, by Arthur Conan Doyle
- The Memoirs of Sherlock Holmes, by Arthur Conan Doyle
- The Hound of the Baskervilles, by Arthur Conan Doyle
- The Return of Sherlock Holmes, by Arthur Conan Doyle
- The Valley of Fear, by Arthur Conan Doyle
- His Last Bow, by Arthur Conan Doyle
- The Case-Book of Sherlock Holmes, by Arthur Conan Doyle
- Die unendliche Geschichte, by Michael Ende
- The Great Gatsby, by F. Scott Fitzgerald
- The Curious Incident of the Dog in the Night-Time, by Mark Haddon
- Catch 22, by Joseph Heller
- The Talented Mr. Ripley, by Patricia Highsmith
- Les Misérables, Victor Hugo
- Brave New World, by Aldous Huxley
- 1984, by George Orwell
- Animal Farm, by George Orwell
- 12 Rules for Life, by Jordan Peterson
- Dr. Jekyll and Mr. Hyde, by Robert Louis Stevenson
- Das Parfum: Die Geschichte eines Mörders, by Patrick Süskind
- Why We Sleep, by Mathew Walker
- On Writing Well, by William Zinsser
@watislaw @notypes Yep that’s very fair
(Originally on Twitter: Thu Jun 02 16:04:19 +0000 2022)
@watislaw @notypes But this
https://twitter.com/watislaw/status/1532380177254187009?s=20&t=FI55wZOiaasTGO7ezfp11Q
does explain why assign can be modelled as always_comb and not always @*.
(Originally on Twitter: Thu Jun 02 15:59:09 +0000 2022)
@watislaw @notypes Yeah OK, I just took their word but it would have been
better with a reference! But OK, I really need to look more at always_comb vs
always @*, because I thought that even with no multidriven and no delays,
assign != always @*.
(Originally on Twitter: Thu Jun 02 15:57:31 +0000 2022)
@watislaw @notypes What’s not quite right? That assign can be modelled as
always @*? Because I think they agree with that in the paper. They really only
say that the standard says that this should be done, but even without
multidriven nets it has inconsistencies.
(Originally on Twitter: Thu Jun 02 15:34:19 +0000 2022)
@notypes This assumes using blocking assignment inside of the combinational always block though. Also @watislaw might be able to add a better explanation!
(Originally on Twitter: Thu Jun 02 15:24:11 +0000 2022)
@notypes Meredith et
al. (https://ieeexplore.ieee.org/abstract/document/5558634) try to address
this. They state the Verilog standard basically says that the semantics of
assign x = y; should be handled like
always @* x = y; But say that this can lead to
inconsistencies between the “hardware semantics” and simulation
(Originally on Twitter: Thu Jun 02 15:20:36 +0000 2022)
I have also now created a poster for @splashcon about our paper on “Formal Verification High-Level Synthesis” that we are presenting on Friday 22nd at 20:05 BST at OOPLSA'21! Here is a summary thread about the paper. 1/7
https://yannherklotz.com/docs/splash21/poster.pdf
(Originally on Twitter: Mon Oct 18 11:38:55 +0000 2021)
FPGAs are a great alternative to CPUs for many low-power applications, because the circuit can be specialised to each application. An FPGA is traditionally programmed using a logic synthesis tool by writing in a hardware description language like Verilog. 2/7
(Originally on Twitter: Mon Oct 18 11:38:55 +0000 2021)
However, writing Verilog can be quite daunting if one doesn’t have hardware design experience, and it can also take a long time to test and get right.
One alternative to this is high-level synthesis (HLS), allowing you to write C which will get translated into Verilog. 3/7
(Originally on Twitter: Mon Oct 18 11:38:56 +0000 2021)
Current HLS tools focus on generating optimal Verilog, however, they can be quite unreliable because of that, negating any testing that was done on the C code. This means the generated Verilog needs to be thoroughly tested again. 4/7
(Originally on Twitter: Mon Oct 18 11:38:56 +0000 2021)
Our solution is Vericert, a formally verified HLS tool, so that any guarantees made in C also automatically translate to the Verilog code. Vericert is based on the CompCert C compiler, so that it can translate C code into Verilog. 5/7
(Originally on Twitter: Mon Oct 18 11:38:56 +0000 2021)
The bad news is that we are 27x slower than an existing optimised HLS tools when divisions are present, as we implement divisions naïvely in Verilog.
However, the better news is, with division implemented as an iterative algorithm, we are only 2x slower. 6/7
(Originally on Twitter: Mon Oct 18 11:38:57 +0000 2021)
If you are interested in knowing more, I have added links to a blog post, our paper, and our GitHub repository: 7/7
- https://vericert.ymhg.org/2021/10/a-first-look-at-vericert/
- https://doi.org/10.1145/3485494
- https://github.com/ymherklotz/vericert
(Originally on Twitter: Mon Oct 18 11:38:57 +0000 2021)
@jinxmirror13 @CamlisOrg @kaixhin @LboroVC Congrats!!! Enjoy attending in person! 🎉
(Originally on Twitter: Sat Oct 09 21:59:46 +0000 2021)
@lorisdanto Thanks!
(Originally on Twitter: Sat Oct 09 21:57:45 +0000 2021)
@jinxmirror13 Thank youu!!
(Originally on Twitter: Sat Oct 09 21:57:35 +0000 2021)
I have finally gotten around to writing an introductory blog post about Vericert, our formally verified HLS tool that we will be presenting on Friday 22nd at OOPSLA'21!
https://vericert.ymhg.org/2021/09/a-first-look-at-vericert/
(Originally on Twitter: Sat Oct 09 13:22:44 +0000 2021)
@watislaw @jfdm That sounds really interesting actually. I have realised that I don’t really know too much about the details of synthesis myself, so might try building a simple one using Lutsig as an example.
(Originally on Twitter: Mon Sep 13 15:25:45 +0000 2021)
@jfdm Which parts did you find hand wavy?
I hope it does, but the main overlap between this and Lutsig is the Verilog semantics, and we only really go into details about the differences.
(Originally on Twitter: Mon Sep 13 11:53:49 +0000 2021)
Just finished the camera ready version of our (with @wicko3, @nadeshr5 and James Pollard) paper “Formal Verification of High-Level Synthesis”, which will be presented at OOPSLA'21 @splashcon!
Stay tuned for a blog post about this paper soon.
https://yannherklotz.com/papers/fvhls_oopsla21.pdf
(Originally on Twitter: Mon Sep 13 10:12:20 +0000 2021)
Although my supervisor @wicko3 has already written a great summary of the paper!
https://johnwickerson.wordpress.com/2021/08/27/vericert/
(Originally on Twitter: Mon Sep 13 10:12:20 +0000 2021)
@gabeusse @gconstantinides @imperialcas @jianyi_cheng* @Stanford @UCLA *@Penn Yep, our short paper preprint is available here:
https://yannherklotz.com/papers/esrhls_fccm2021.pdf
(Originally on Twitter: Tue May 11 19:39:03 +0000 2021)
RT @wicko3: Here is a short blog post about an #FCCM2021 paper that will be presented next week by @ymherklotz about our work (with Zewei D…
(Originally on Twitter: Fri May 07 14:12:33 +0000 2021)
@wicko3 I’ll have to read that then, it seems like it is a very nice introduction to concurrent computation as well.
Bigraphs seem really interesting though because such a visual representation can describe distributed computations.
(Originally on Twitter: Tue Dec 22 22:50:44 +0000 2020)
@wicko3 Oh interesting! I haven’t heard of those before, but it makes sense that there is a formalisation.
(Originally on Twitter: Tue Dec 22 22:32:39 +0000 2020)
Decided to write a bit about a note-taking method that finally seems to work for me, following closely how Niklas Luhmann took his notes in his famous Zettelkasten. Currently using #emacs with #orgmode which works perfectly for it.
https://yannherklotz.com/blog/2020-12-21-introduction-to-luhmanns-zettelkasten.html
(Originally on Twitter: Mon Dec 21 22:15:39 +0000 2020)
@gconstantinides Thank you! Glad to have had such a great discussion.
(Originally on Twitter: Tue Nov 17 18:04:05 +0000 2020)
@watislaw I was actually doing the same which is why I came across this weird behaviour. I think this is a similar example to the one I gave, where single always blocks never recurse, and therefore don’t update signals again. Here when they are separated they never reach a steady state.
(Originally on Twitter: Wed Oct 21 09:53:35 +0000 2020)
@watislaw Yes that’s true, and I think in this case they do actually follow the standard correctly, even though I would expect them to recurse in the same always block when signals in the sensitivity list change and maybe reach some steady state, although I don’t know how feasible that is.
(Originally on Twitter: Tue Oct 20 14:33:36 +0000 2020)
@watislaw That’s exactly what I was looking for actually, I must have missed it in the standard, thanks! I was looking in the combinational circuits part.
(Originally on Twitter: Tue Oct 20 14:30:24 +0000 2020)
However, synthesis tools will produce the following netlist, where the input is directly connected to the output. Is this a bug in the simulator or the synthesis tool? Or is this mismatch correct and should that be the case?

(Originally on Twitter: Tue Oct 20 13:56:08 +0000 2020)
What should the following Verilog design produce?
Should it be a latched shift register, where the output is equal to the previous input?
Or should it be a direct assignment from input to output?
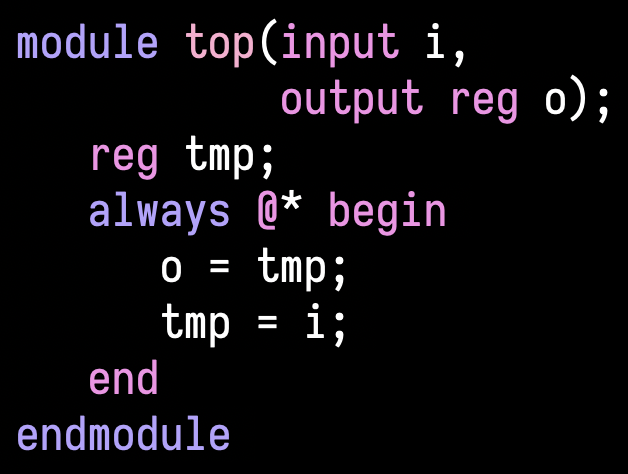
(Originally on Twitter: Tue Oct 20 13:56:07 +0000 2020)
Even this simple piece of Verilog has ambiguities in Simulation and Synthesis.
Simulators will just execute the always block when the input changes, and the output will therefore be set to the previous value of the input.
The whole testbench is here:
https://gist.github.com/ymherklotz/e8600f8c2e1564f4679fe3a99146a874
(Originally on Twitter: Tue Oct 20 13:56:07 +0000 2020)
Vericert is written in Coq and will allow for a trustworthy, verified translation from C to Verilog using CompCert as the front end.
This eliminates the need to manually verify the correctness of the generated hardware, which is tedious and expensive.
(Originally on Twitter: Fri Jul 24 10:59:29 +0000 2020)
We just made our (James Pollard, @nadeshr5, @wicko3) work-in-progress formally verified high-level synthesis tool Vericert public!
https://github.com/ymherklotz/vericert
(Originally on Twitter: Fri Jul 24 10:59:28 +0000 2020)
@kumastz @wicko3 Thanks!!
(Originally on Twitter: Thu Jun 18 21:18:49 +0000 2020)
@Helidcotor22 @wicko3 Thank you!
(Originally on Twitter: Thu Jun 18 21:17:35 +0000 2020)
I really enjoyed the student research competition at #PLDI2020 enjoyed talking to everyone who came by my poster and also got great feedback from the judges! https://twitter.com/wicko3/status/1273710075966885889
(Originally on Twitter: Thu Jun 18 21:07:12 +0000 2020)
Really enjoyed presenting our work on fuzzing synthesis tools at #FPGA2020 https://twitter.com/gconstantinides/status/1232464094659104768
(Originally on Twitter: Wed Feb 26 00:46:38 +0000 2020)
@wicko3 I’m guessing because it’s a package manager for *nix systems. Makes it really hard to google for errors though because it just comes up with linux search results.
(Originally on Twitter: Sun Feb 16 21:32:52 +0000 2020)
Been using Coq with OCaml extraction lately, with various dependencies for both and have found Nix really useful to build the project reliably and on different platforms.
Wrote a post on how to set up a quick derivation for Coq.
https://yannherklotz.com/blog/2020-02-15-nix-for-coq-development.html
(Originally on Twitter: Sun Feb 16 21:02:29 +0000 2020)
Congratulations Dr. He Li !!!!
https://twitter.com/DrHelicopter2/status/1228018755072073729
(Originally on Twitter: Thu Feb 13 23:14:18 +0000 2020)
@fangyi_zhou_ You could try out Nix, been working great for me for Coq and Ocaml.
(Originally on Twitter: Wed Feb 05 09:08:02 +0000 2020)
@jianyi_cheng Looking forward to the presentation!
(Originally on Twitter: Mon Dec 16 00:59:07 +0000 2019)
The final version of our FPGA ‘20 paper “Finding and Understanding Bugs in FPGA Synthesis Tools” is now ready.
We added many more runs for various Yosys versions and have now managed to properly test Quartus.
https://yannherklotz.com/papers/fubfst_fpga2020.pdf
(Originally on Twitter: Sun Dec 15 19:49:49 +0000 2019)
Congrats Sina!!
https://twitter.com/sinaxs/status/1205115213411950595
(Originally on Twitter: Sat Dec 14 20:47:10 +0000 2019)
@tom_verbeure @johnregehr @whitequark @oe1cxw* Most of the bugs found in *Yosys were in the optimisation passes, which I don’t think are applied when *Yosys passes the design to ABC or an SMT solver, so these were not affected. We *are looking into using multiple equivalence checkers so that these are tested *at the same time.
(Originally on Twitter: Mon Nov 11 17:43:51 +0000 2019)
@johnregehr @whitequark @oe1cxw Link to VlogHammer:
http://www.clifford.at/yosys/vloghammer.html
There is also a random Verilog generation tool called VERGEN from 2003, but I don’t think it was used to fuzz existing tools properly.
(Originally on Twitter: Mon Nov 11 17:14:13 +0000 2019)
@johnregehr @whitequark @oe1cxw has written a tool called VlogHammer which focused on fuzzing expressions in synthesis tools and also reported many bugs to these vendors. However, these took a long time to fix in commercial tools and some still are not fixed.
(Originally on Twitter: Mon Nov 11 17:09:50 +0000 2019)
@jrenauardevol @johnregehr @mithro Yes, currently hosted on github:
https://github.com/ymherklotz/verismith
(Originally on Twitter: Mon Nov 11 16:05:08 +0000 2019)
Currently working on my Entity Component System for my game engine! More info at
https://github.com/ymherklotz/YAGE
(Originally on Twitter: Mon Jun 18 23:47:43 +0000 2018)
** Photos
** News
** Paper Changelog
A small collection of changelogs for papers that were published. These explain the differences between the local copy on this website and the published version of the article on the ACM or IEEE.
They will normally cover very small changes which are not going to be updated in the published version of the article.
** Changelog Content
*** OOPSLA'21: Formally Verified High-Level Synthesis
**** 2022-06-28
- Section 2.2, §3
- This section mentioned a variable
xwhich should have actually beentmp.
Thanks to Joseph Turner for refactoring the
ymhg/incr-idfunction and correcting the description of incrementing past 9. ↩︎